Semantic Caching: Cost Reduction and Accuracy Risks in LLMs
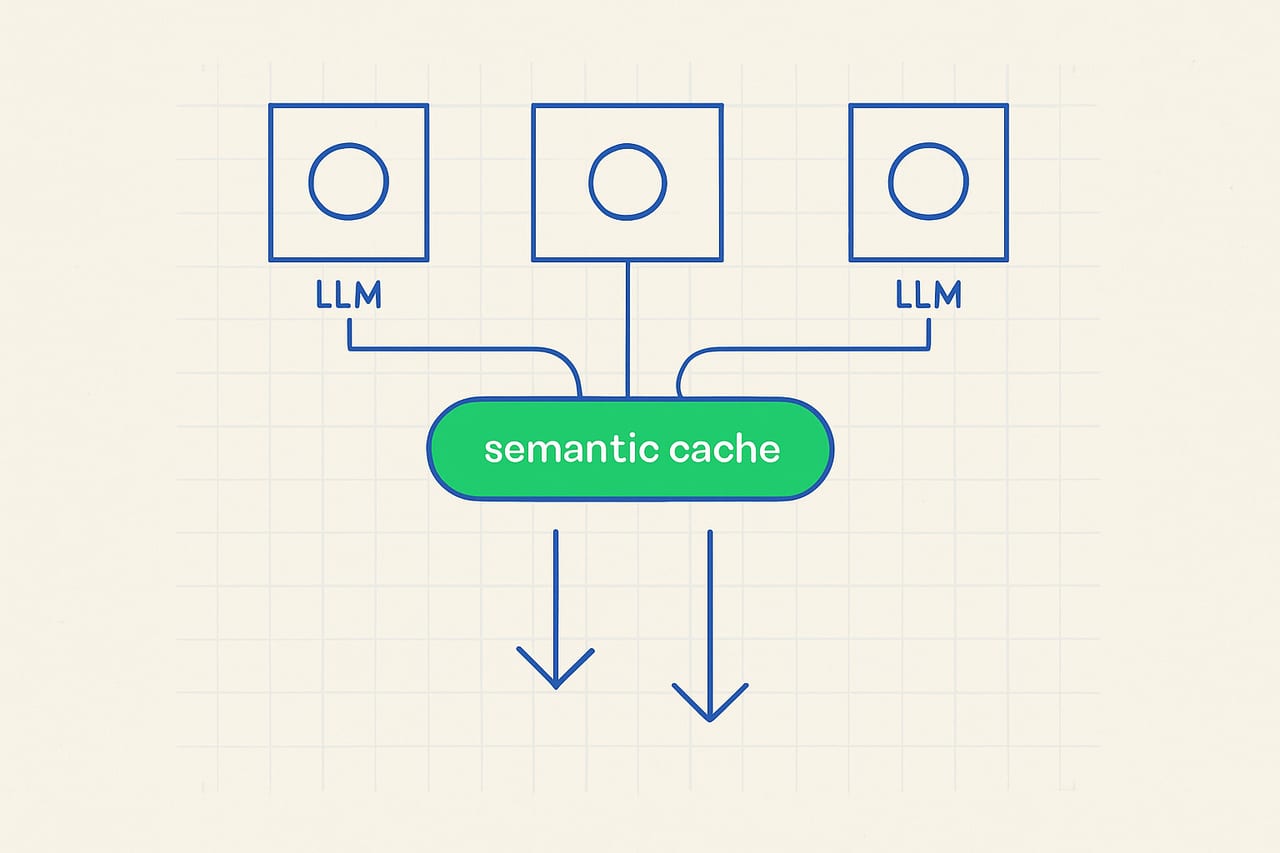
- Semantic caching can reduce LLM operational costs by up to 70%.
- Improperly configured caching may lead to incorrect responses.
- Implementing semantic caching requires careful trade-off analysis.
- Effective monitoring is crucial to avoid pitfalls of stale data.
The problem
Startups leveraging Large Language Models (LLMs) often face overwhelming operational costs, particularly during high-traffic periods. The expense of repeated API calls for similar queries can rapidly escalate, especially in industries reliant on real-time data processing and user interactions. For instance, a customer support application querying an LLM for similar inquiries can incur significant charges, negatively impacting the startup's runway and scalability.
What we found
Through extensive analysis, we discovered that semantic caching—storing responses based on the semantic similarity of queries—can drastically reduce costs by up to 70% when implemented correctly. However, this technique introduces a risk: if not managed properly, cached responses may lead to inaccuracies, particularly if the underlying data changes or if user queries evolve. This duality of cost-saving and potential misinformation reframes how startups should approach LLM deployments.
How to implement it
To implement semantic caching effectively, follow these steps: First, establish a semantic similarity threshold using techniques like cosine similarity or embeddings via models such as Sentence-BERT. Next, configure your caching layer using tools like Redis or Memcached to store responses associated with similar queries. Ensure that your caching mechanism can expire entries based on a TTL (Time-To-Live) strategy to mitigate stale data risks. Finally, integrate logging and monitoring to track cache hits and misses, using tools like Grafana for real-time insights.
How this makes life easier
By adopting semantic caching, startups can significantly reduce their LLM-related operational costs while improving response times. With a potential decrease in API calls, companies can redirect funds towards innovation rather than infrastructure. Moreover, faster response times enhance user experience, leading to higher retention rates and satisfaction.
Accuracy trade-offs and pitfalls
While semantic caching provides substantial cost benefits, it is essential to recognize the trade-offs involved. Cached responses may not reflect the most current information, particularly in dynamic environments. This can lead to incorrect answers being returned to users, compromising trust and reliability. Startups should conduct regular audits of cached data and implement fallback mechanisms that query the LLM for fresh responses when accuracy is paramount.
Figures are industry-typical ranges for these techniques, not guaranteed results — actual numbers depend on your workload.
The solution
Startups should implement semantic caching strategically, weighing the cost benefits against potential accuracy risks. Regular monitoring and a proactive caching strategy can optimize performance while maintaining user trust.
FAQ
How do I know if semantic caching is right for my application?
Evaluate your application’s query patterns and frequency. If you observe a high rate of repeated queries, semantic caching could be beneficial. Conduct a cost analysis to compare potential savings against the risks of inaccuracies.
What tools can I use for semantic caching?
Popular tools include Redis for caching and Sentence-BERT for semantic similarity computations. These can be integrated into your existing architecture with minimal overhead.
How frequently should I refresh my cache?
The refresh rate depends on the volatility of your data. For static datasets, a longer TTL may suffice, while dynamic data requires shorter TTLs to ensure accuracy.
What are the signs of stale cache data?
Monitor user feedback for inaccuracies and track cache hit rates. A significant drop in hits may indicate that cached data is becoming outdated or irrelevant.
Want help to cut AI & LLM costs without cutting quality?
This is exactly what our AI & LLM cost engineering work covers. Book a build audit and we'll map it against your real architecture and cost curve.
Book a Build Audit